
By CPA Derrick Majani
Robust Systems Perform Well In The Presence Of Unexpected Events
The real-world rate of change affecting almost everything to do with data is what separates the theory of
enterprise data resilience from its practice. Change is not only inherent in the dynamics of the problems to be solved with data, but also in the dynamics of a host of data-related activities and considerations: data sourcing, collection and categorization; data storage on-premises or in the cloud; data governance and its associated disciplines to ensure fit-for-purpose data; the types of analytics or artificial intelligence (AI) models used; and the model training applicable for insight development and decision-making.
Data can be affected by expected and unexpected changes in everything from hardware and software components to regulatory, sociopolitical and community requirements. Ultimately, it is how the enterprise plans for and reacts to change that determines the effectiveness of its data resilience strategy. Furthermore, the inevitability of change, or drift, means that even the most well-laid plan for enterprise data resilience must frequently be reviewed to ensure its effectiveness. Real-world data resilience can, thus, be defined as the ability (or set of processes) to transmit or store information in a manner that supports processing to rebound from an adverse event.
There are multiple levels of data resilience, as shown in figure 1. In practice, data resilience encompasses more than the general commercial definition of the term, which addresses the role of cloud in data availability—a single dimension of data resilience
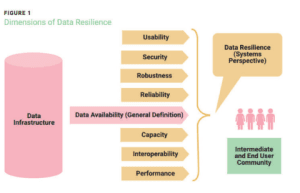
AI, data governance and the cloud are, therefore, inextricably linked to data resilience. This strategic construct accentuates an emerging need for standards that better enable the link between theseconverging technologies and data resilience. Furthermore, recognizing that data are at the heart of each of these concepts means that the converged technologies need to be the focus of an organization’s data resilience strategy to best enable the role of data in the enablement of the organization’s enterprise strategy and in sustaining operational continuity.
AI, data governance and the cloud are, therefore, inextricably linked to data resilience. This strategic construct accentuates an emerging need for standards that better enable the link between these converging technologies and data resilience.
Data Resilience Plan Review

Conclusion
The pandemic has shed a light on many organizations’ data shortcomings, with 93 percent of enterprises having experienced the impact of poor data management (as reflected by some of the dimensions of data resilience shown in figure 1) as a consequence. Supply chains have been so impacted by the pandemic that data resilience has been adopted as a risk mitigation strategy,with controls for factors such as data integrity data storage, data use, cybersecurity and data disruption being identified as fundamental to improving supply chain data integrity.
Data resilience is not only about being able to bounce back from, say, adverse availability and security events using cloud technology. Rather, data resilience is also about the data integrity safeguards that are fundamental to trustworthy AI and the reliance of good AI on good data governance. Caution should be exercised with respect to single cloud solutions for data resilience. Further, the cloud does not address all the dimensions of data resilience; data governance in the cloud is more complex than on-premises data governance and drift can significantly compromise the effectiveness of an organization’s entire data resilience plan.
Given the real-world dynamics between data resilience, AI, data governance and data integrity—and the direct or indirect impact of those dynamics—drift in any one dimension in any one of these disciplines can significantly impact any or all of the other disciplines. The implications need to be managed in the interest of appropriately securing enterprise data resilience. Two words come to mind in the context of managing drift in a systems context as far as it relates to data resilience: robustness and re-configurability. Robust systems perform well in the presence of unexpected events, while reconfigurable systems cost-effectively permit new or modified capabilities in response to drift.
Resilience-based management is a higher order activity than risk-based management, given the ambiguous
(vs. uncertain) nature of potential incidents. Sound real-world data resilience depends on system and data management designs that can operate well outside of their original design parameters, with component parts that can be rearranged to produce new capabilities in the event of adversity.
Because true robust system design is often prohibitively expensive, the need for an increasingly reconfigurable environment in the interests of resilience is pressing. The value of a loosely coupled IT architecture—a paradigm already embraced in leading organizations—is evident. An organization that already practices loose coupling is in a very good position to establish the structures required to practice effective real-world data resilience.


